
01 引言——ChatGPT与“中文房间”
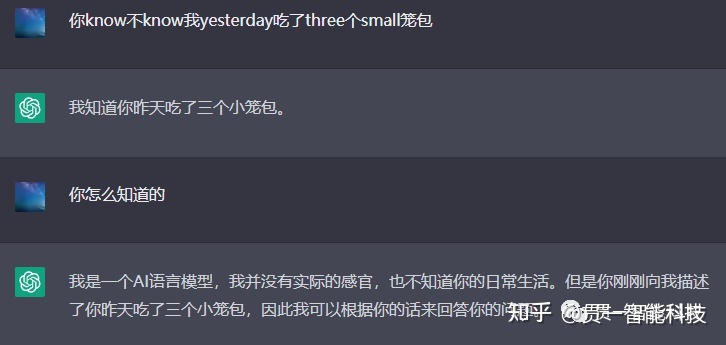
每个实际用过ChatGPT的人,都会被其展现出的强大对话能力所折服,甚至不少人认为它已经懂得了如何思考,产生了自我意识。 在解答这个问题之前,我想请大家想象这样一个场景:一个完全没学过中文的人被关在一个封闭的房间,房间里有一本手册,照着这本手册的指示,就能够针对任意中文问题给出像模像样的中文回答。外面的人在纸条上写好中文问题递进去,屋里的人照着手册拼凑出中文回答递出来。这样,在外面看来,屋里的人是懂中文的,可事实果真如此吗?这就是由著名哲学教授约翰瑟尔所提出的“中文房间”思想实验。
02 ChatGPT的G——生成式模型(Generative model)
每当你对ChatGPT提出一些超出它能力范围的要求时,它都会以“我只是一个语言模型”为由婉拒你的指令。语言模型是什么?用最通俗的话讲,就是给定上文,预估下一个词出现的可能性。 这其实也是我们人类的语言能力之一,每当我们听到爷爷说:“不听老人言”,就知道他接下来百分百要说“吃亏”。妈妈说:“早上让你带伞你不带,结果...”,就能猜到下一个词极有可能是“下雨”或者“挨淋”。这个过程并不需要任何语法或逻辑上的解析,单纯就是听的次数太多而形成了一种直觉经验。 同样,只要我们搜集足够多的句子给计算机看,它就也可以模拟这种经验,用接龙的方式不断生成单词并构造出句子,这就是chatGPT的G—生成式语言模型。它所做的唯一一件事就是:基于上文生成下一个单词,再把这个单词加入上文生成下一个,如此往复。 很多人对ChatGPT的文本生成方式存在误解,以为它是从知识库中搜索并拼凑出结果,但事实上,对于ChatGPT来说,既不存在所谓的“知识库”,生成结果也不是简单搜索拼凑,而是通过计算得来的。 这里我可以举一个小学生都能看懂的例子来简化它的实际计算过程,假如我们规定早=1,上=2,好=3,坏=4,以及两个未知数x和y。
03 ChatGPT的T——变形器(Transformer)
这种语言模型固然很好,但在相当长一段时间,都无法从根本上解决人类语言的长距离依赖问题。 比如这个句子:“他发现了隐藏在这个光鲜亮丽的显赫家族背后令人毛骨悚然的____”。你大概率会填“秘密”。 但前面的哪个词决定了你填“秘密”?是定语“令人毛骨悚然的”吗?显然不是,因为这样的话,你可以填“照片”、“传统”、“讯息”、“故事”、“游戏”等一大把词。 真正起到关键性作用的,是前面的谓语动词“发现”,再配合“隐藏”和“背后”这两个词,对“秘密”的生成产生了极强的约束力。 但对普通的生成式语言模型来说,上文单词离得越远,对生成下一个词所起到的作用越是微乎其微。 直到2017年,谷歌机器翻译团队在论文《Attention is All You Need》中,首次提出了transformer架构和注意力机制。所谓注意力机制,就是人脑在接收信息时,并不会处理全部,而是选择性地关注信息的关键部分。比如我问你下面这张图片是什么动物。
04 ChatGPT的P——预训练模型(Pre-trained model)
直到这里,AI的学习都是不需要任何人工干预的,只要喂给它足够多的文本就行,这种训练方式叫做无监督学习(Unsupervised learning)。 那么OpenAI用了多大的文本量喂给AI呢?答案是45T。这是什么概念?四大名著加起来350万字,按utf8编码,大约10M左右。45T等于47185920M,也就是相当于472万套四大名著的文本量。
05 ChatGPT的chat——人类反馈强化学习(RLHF)
其实,OpenAI早在2020年就发布了这个预训练模型——GPT3,也就是说,早在两年前它就已经拥有了chatGPT的绝大多数能力,可为什么当时没有在人工智能的小圈子外掀起任何波澜呢。我认为,其中的奥妙就在于交互方式,人类更倾向于将“与自己的相似度”作为衡量智能的指标。只要看起来像人,说起话来像人,哪怕是像索菲亚那样的弱智机器人,也能通过炒作假新闻骗到公民身份。

06 结语
以上就是ChatGPT的基本原理,原理本身虽然简单,却综合运用到了无监督学习、监督学习和强化学习等多种训练手法,训练语料囊括了全球互联网2021年以前的海量优质文本,训练过程也融会贯通了几十年来在算法方面的积累,并加入了各种工程学技巧,可谓集大成之作。可能有人会说:“你既然这么明白,怎么没搞个出来?”挺好的问题,但我觉得更应该思考的是:“为什么像百度腾讯阿里华为这样不缺钱不缺人的大厂,没有率先搞出来?”。ChatGPT为什么没诞生在中国?除了技术原理之外,是否还存在其他壁垒?中国是否有能力复现?事到如今还有没有必要复现?到底能不能弯道超车?等等。 贯一智能科技 - 知乎本站内容收集整理于网络,多标有原文出处,本站仅提供信息存储空间服务。如若转载,请注明出处。
 ChatGPT助力人工智能教学,教师要如何使用?
ChatGPT助力人工智能教学,教师要如何使用? Deepseek 能否替代 ChatGPT?我在处理地理空间任务中试了试
Deepseek 能否替代 ChatGPT?我在处理地理空间任务中试了试 chatGPT-4手把手教写2022高考英语作文,这能力绝绝子!
chatGPT-4手把手教写2022高考英语作文,这能力绝绝子! 中学教师如何使用豆包、GPT、Kimi等AI工具提高工作效能
中学教师如何使用豆包、GPT、Kimi等AI工具提高工作效能 FunAI、ChatGPT、Quizlet,人工智能(AI)自动答题软件有哪些?
FunAI、ChatGPT、Quizlet,人工智能(AI)自动答题软件有哪些? 使用ChatGPT写学术论文10大分步润色技巧
使用ChatGPT写学术论文10大分步润色技巧 如何快速使用ChatGPT产出一篇高质量论文?全流程在此
如何快速使用ChatGPT产出一篇高质量论文?全流程在此 ChatGPT使用技巧:6步搞定一篇优质论文
ChatGPT使用技巧:6步搞定一篇优质论文




